cedar:一个通用可编程数据流水线框架
cedar: Composable and Optimized Machine Learning Input Data Pipelines
这篇文章发表于arXiv24,作者是Emanuel Adamiak,Mark Zhao,Christos Kozyrakis,机构是Stanford。
本文主要针对数据流水线的欠优化问题,设计了一个集成多种数据流水线优化的、通用的数据流水线框架cedar。
1. 问题背景
针对不同的模型,有不同的数据处理方式。如果是传统分布式的方法,会将方法都离线实现,分布式的worker互不通信。但是数据处理的方法很多,如果都提前实现是不可能的。目前,为了提高训练数据的吞吐量,尤其是在预处理上形式多样的情况下。很多公司都采用了低效的方法,用分布式的框架,使用大量处理器来服务一个训练GPU,浪费了很多硬件。
另外,现在的算子库虽然有很多有点,但是方法分散、针对特定的ML框架、而且不够聚合。比如tf.data只能用于tensorflow计算图。而且对后来的扩展能力也不够好。
本文提出的编程框架cedar,可以:
- 让数据管道的设计者自由组合各种数据处理算子。并进行优化。Python原生API,可以和任何框架一起使用。
- 把pipeline转换为静态计算图,从而进行优化和运行时调优(结合可扩展的优化策略)。
- cedar可以把优化的数据管道接入到不同的后端执行。比如TF,PyTorch,MXNet等。来平衡最佳的后端性能
2.问题描述
ML系统的数据输入有两部分组成:
- 在训练前,采用离线方法讲原始数据通过特征工程转换为结构化的数据,这个过程中由于不依赖训练,因此使用传统的分布式处理系统进行。
- 在训练过程中,需要把本地存储、云端存储等地方的数据根据训练任务的需求打包成tensor输入。而且在训练过程中的数据处理要调用多种包的多种操作。
现有ml系统都是使用框架自带的数据处理库,比如tf.data,torch.data等。但是这些库难以更新高吞吐量的优化算法。而且这些库都是针对特定框架的,不够通用。
3.前提实验
实验表明,不同的优化算法,如果在pipeline上使用他们的话,其实是有一定的复杂性的。
- 对offload而言,其对于使用多线程的方式比较敏感。在多线程时,本地卸载好于remote卸载,但是如果只写在高计算密度的内容,则对性能影响不大。
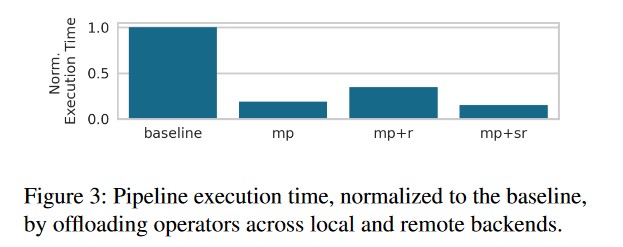
- 对fusion而言,其对于不同的数据处理算子的组合有不同的性能影响。如果把灰度融合放在远程执行,会增加多余IO(本地执行的效果更好)。而如果融合计算密集的算子,则会提高计算速度。
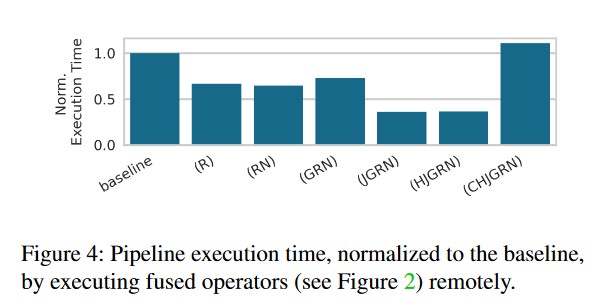
- cache操作也有影响,如果cache一个int8到fp32的转化,本来传输int8即可,现在需要传输fp32,会增加数据传输量。对于cv来说,缓存中间数据是无效的。
- 理论上来说,重排序可以加速模型执行效率(例如先降低数据量),但是如何让系统决定哪种重排序合法是关键。
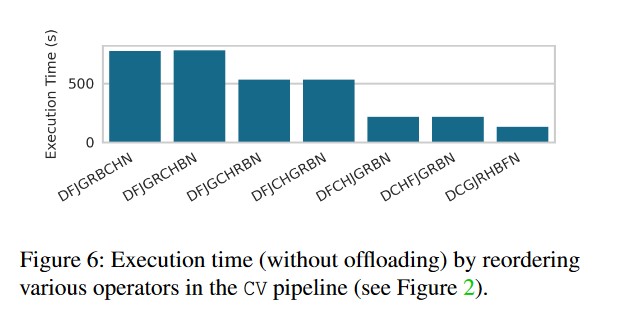
- 数据预加载,可以提高吞吐量并覆盖加载空闲。尤其是和卸载等方法同时使用
总的来说,不同优化算法如果整合起来,可以提供更大的吞吐量提升,但是过多方法的组合使搜索空间过大,因此需要一个系统来执行优化的组合方法。
4. cedar
一个cedar的基本流程如下: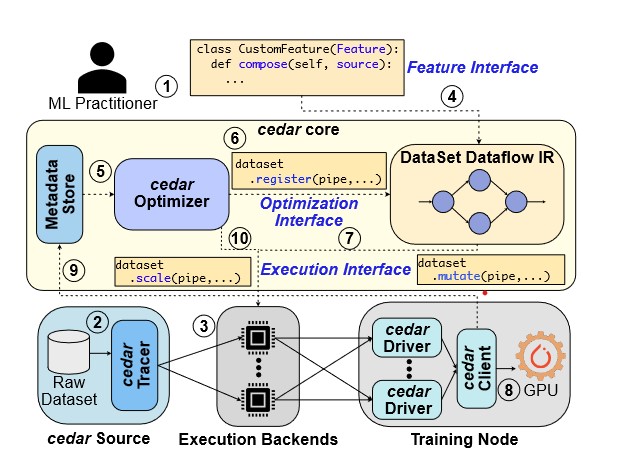
其中可以分为以下步骤:
- 用户定义一个静态处理管道
- 用户定义raw data数据
- 指定执行后端
- 创建cedar Dataset并编译成IR
- 通过profile来优化策略
- 静态修改IR
- 在运行时分配给执行后端
- 通过后端组合的client来交付训练框架进行训练。
- 通过训练的统计数据来进行反馈,修改计算图
总体而言,cedar是一个静态的优化器,只是在不同的step或epoch间修改了计算图。
数据处理(Feature)API
cedar提供了pipe组件库,可以级联成feature。pipe包含基本的数据加载、转换等、支持输入输出流。
这是一个高度抽象的库,只包含了原语级的操作,比如map、filter、reduce等。这样可以让用户自由指定后端。通过提供一个懒加载的实现,来逐个为ML框架提供mini-batch。
然后,通过指定计算的依赖关系,来进行拓扑排序。值得注意的是其采用的不是一对一的拓扑排序,而是类依赖类的拓扑排序。从而实现更宽松的依赖关系。方便优化。另外还有随机性缓存加入。
为了避免错误,cedar设计了一个UUID来表示每个data sample,并且将sample打包成固定大小,来通过映射压缩UUID的总数据量。当发生错误时,cedar会根据每个sample打包的编号,记录已经部分进入ML框架和没有进入ML框架的数据,通过这种checkpoint来进行数据并行的断点回复(是否可以实现成其他方式的断点恢复?)。
优化与运行接口
cedar通过一些原生库,实现了包括prefetch,cache,fusion等优化的API,都是基于操作pipe的层次。然后使用assign函数来讲执行pipe分配给后端。set_shards用来把Driver分配给Client。
Driver是一个进程,类似协调器,负责分配任务。默认情况下一个client有一个driver。因此,既可以给driver分配多个client,从而让任务跨GPU执行。或者,给client分配多个driver,来让单个client内部并行化不同任务,提高吞吐量。
另外,cedar允许讲一个pipe的工作分配给若干个Variants。Variants是一个可变的后端实现。优化器可以在运行时动态调整这个分配。
5. 优化器
优化器包含静态和动态两部分,静态优化需要在执行前进行。但是二者都需要收集信息。cedar自动收集如下信息用于统计:
- 外部信息
- Sample数据大小
- 当前后端
- 缓冲区大小
- 核心信息
- 基线吞吐量$tput_{base}$
- 本地执行(单driver)作为基线
- pipe延迟$lat_{base}(p)$
- pipe输入输出的sample大小$size_{in}(p)$,$size_{out}(p)$
静态优化
静态优化在最开始把性能提高到最高。简单来说就是把所有优化方法的前端调用一遍,reorder->cache->fusion->offload->prefetch。然后部署到后端。
- reorder: 线性排序,递归寻找最佳顺序,可选考虑输出顺序。
- cache:遍历寻找最佳cache点,优先考虑随机标记算子。
- offload:把所有pipe和后端求笛卡尔积,然后用fusion尽可能聚合每个操作。评价方法就是加速比。在评估时也考虑缓存的影响,因此实验了两种方法。
- prefetch&sharding:尽量塞prefetch,然后在达到硬件IO限制前尽可能塞多进程。
动态优化
动态优化的目的是让资源尽可能节约。例如,prefetch buffer太大,就随机选一个非本地后端的pipe减小parallel规模。或者针对性地补足有瓶颈的传输。
6. 实验
实验主要考虑了这样的几种情况:
- CV-torch
- CV-tf
- GPT-2
- torchtext-GPT2-BPEtokenizer
- TF-text-GPT2-HuggingfaceBPE
- TF-text-GPT2
- ASR:third party library
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!